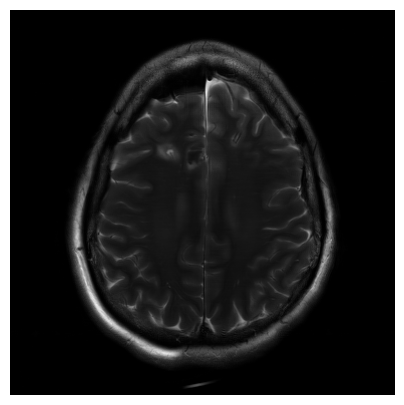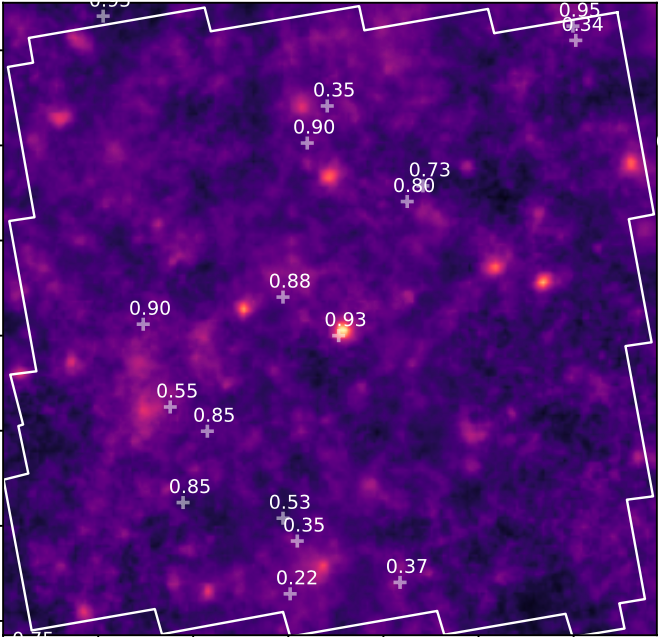
Probabilistic Mapping of Dark Matter by Neural Score Matching
The Dark Matter present in the Large-Scale Structure of the Universe is invisible, but…
J.-L. Starck’s publications
The Dark Matter present in the Large-Scale Structure of the Universe is invisible, but…
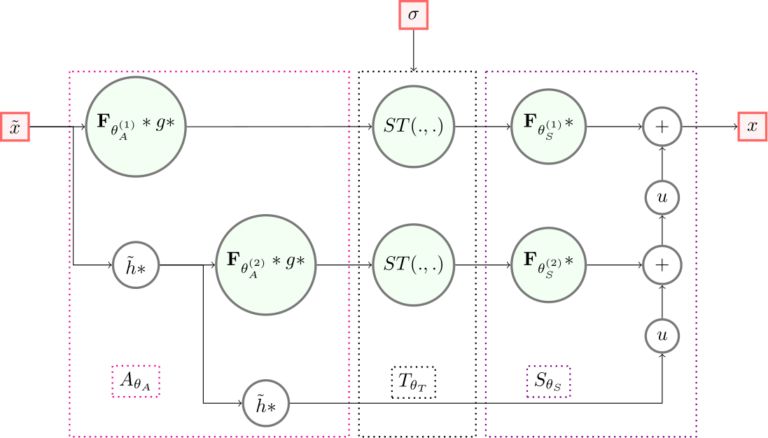
We present a modular cross-domain neural network the XPDNet and its application to the…
Deep neural networks have proven extremely efficient at solving a wide range of inverse…
Sparsity based methods, such as wavelets, have been state-of-the-art for more than 20 years…
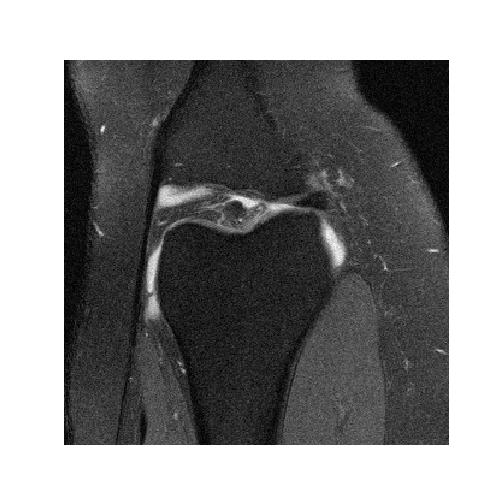
The MRI reconstruction field lacked a proper data set that allowed for reproducible…
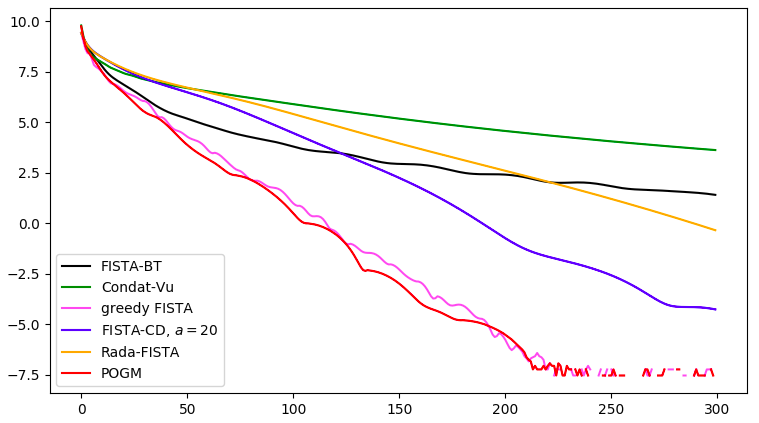
Reference: Z. Ramzi, P. Ciuciu and J.-L. Starck. “Benchmarking proximal methods acceleration enhancements for CS-acquired MR image…
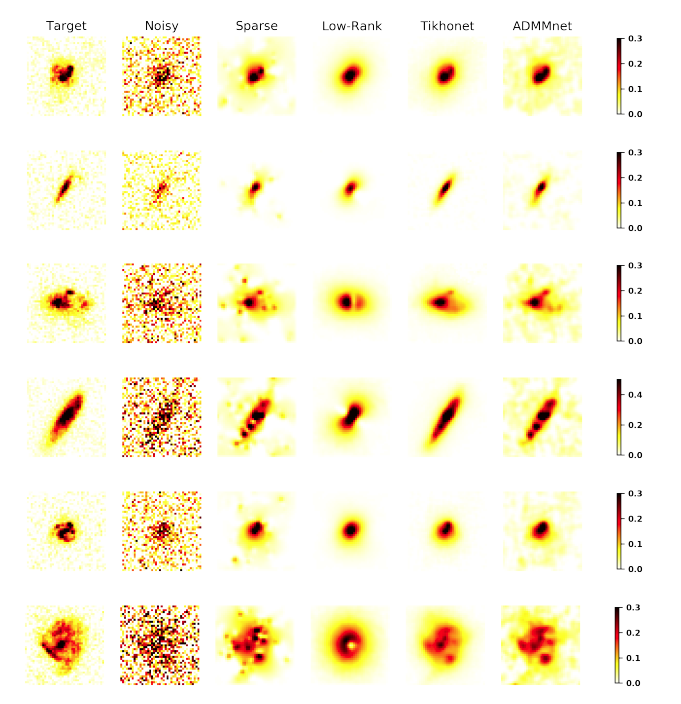
Authors: Khanh-Hung Tran, Fred-Maurice Ngole-Mboula, J-L. Starck Journal: SIAM Journal on Imaging Sciences…
Authors: Florent Sureau, Alexis Lechat, J-L. Starck Journal: Astronomy and Astrophysics Year: 2020…
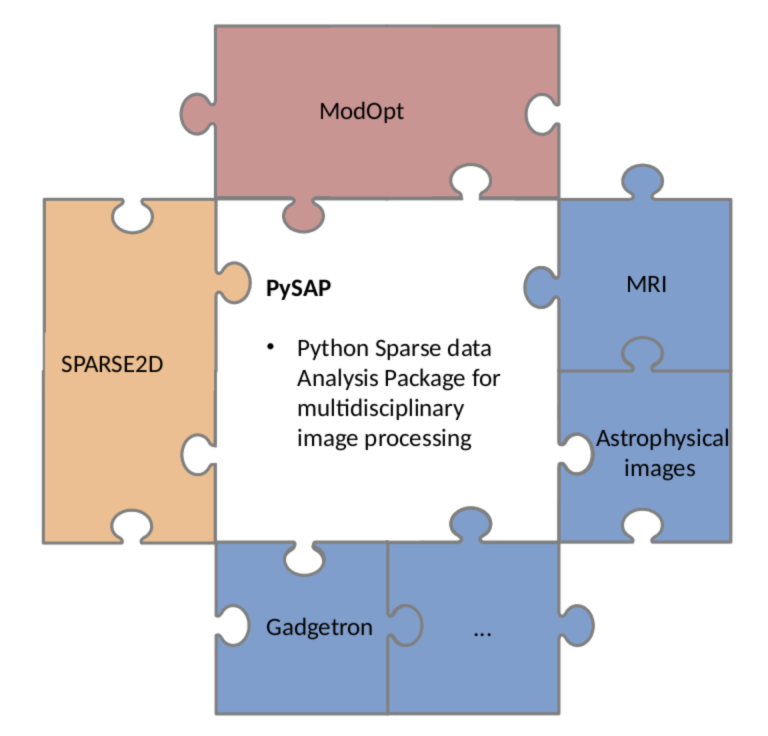
Authors: S. Farrens, A. Grigis, L. El Gueddari, Z. Ramzi, Chaithya G. R.,…
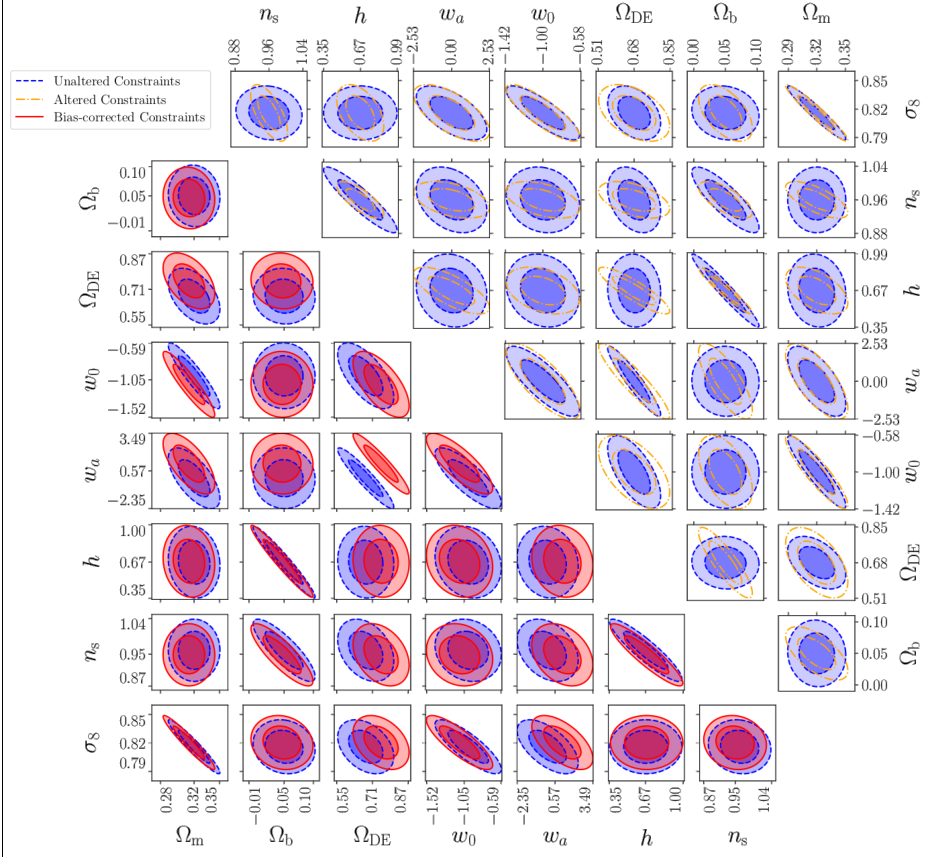
Authors: A.C. Deshpande, ..., S. Casas, M. Kilbinger, V. Pettorino, S. Pires, J.-L. Starck,…