Rethinking data-driven point spread function modeling with a differentiable optical model
Authors: Tobias Liaudat, Jean-Luc Starck, Martin Kilbinger, Pierre-Antoine Frugier Journal: Inverse Problems Year:…
Publications related to PSF estimation and/or image restoration
Authors: Tobias Liaudat, Jean-Luc Starck, Martin Kilbinger, Pierre-Antoine Frugier Journal: Inverse Problems Year:…
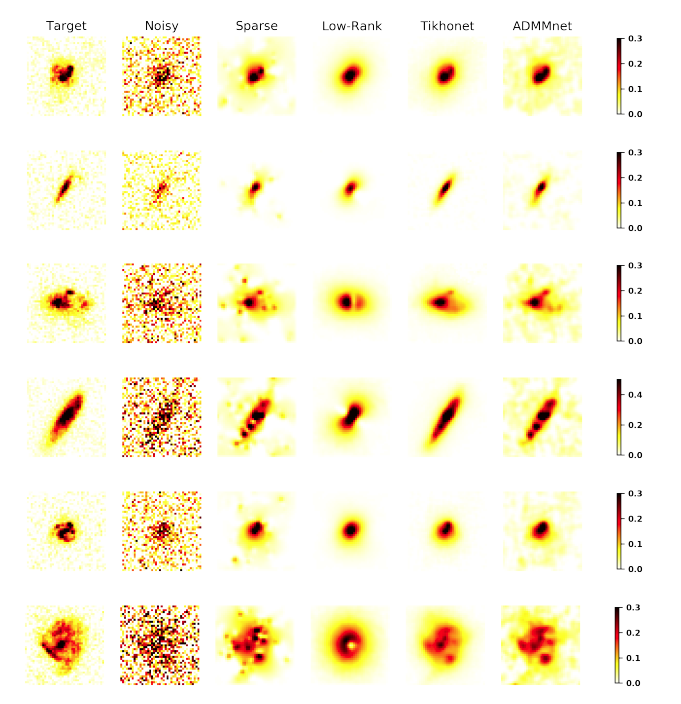
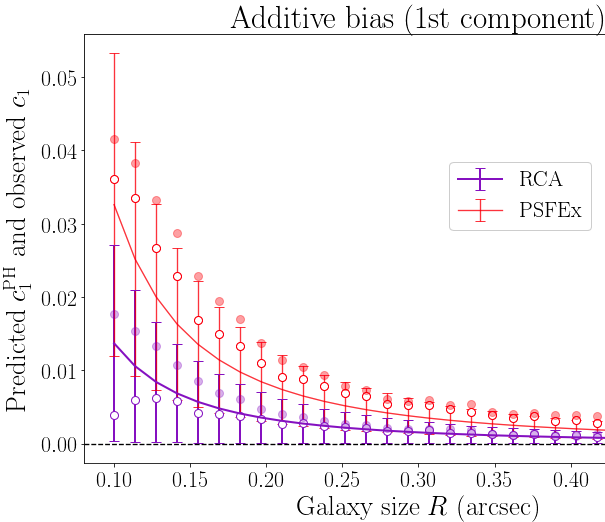
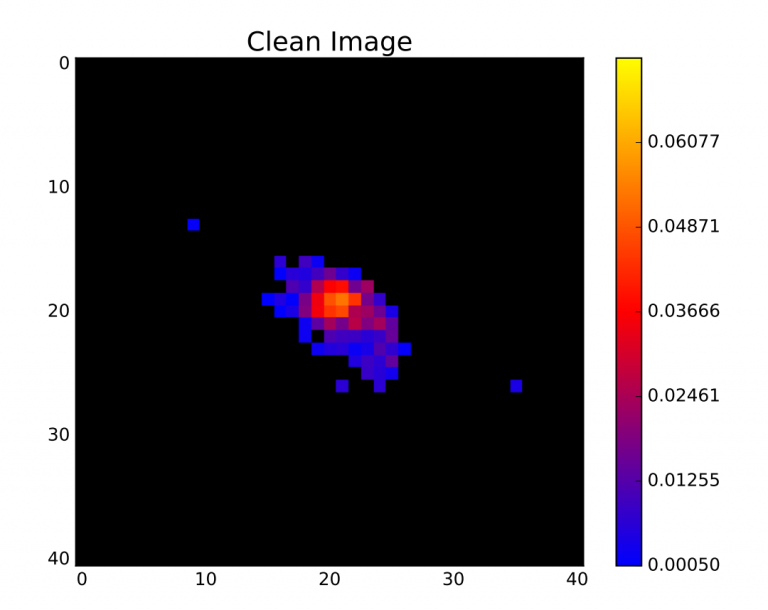
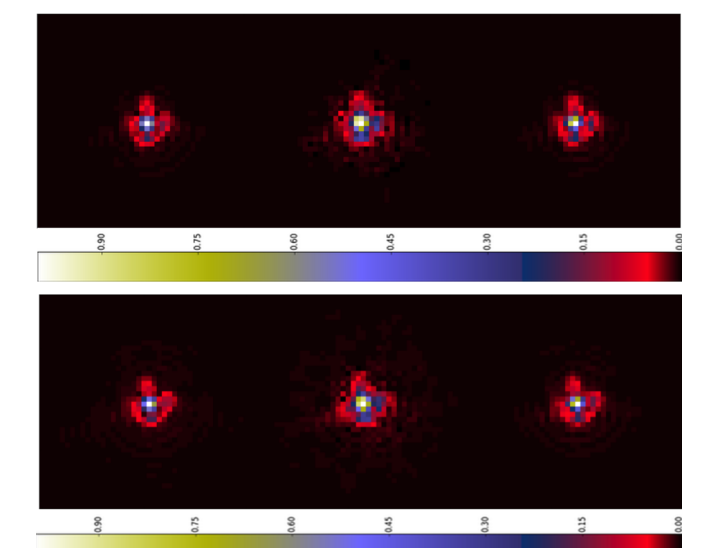
Context. Galaxy imaging surveys observe a vast number of objects that are affected by…
Authors: Florent Sureau, Alexis Lechat, J-L. Starck Journal: Astronomy and Astrophysics Year: 2020…
Authors: M.A. Schmitz, J.-L. Starck, F. Ngole Mboula, N. Auricchio, J. Brinchmann, R.I.…
Authors: A. Panousopoulou, S. Farrens, K. Fotiadou, A. Woiselle, G. Tsagkatakis, J-L. Starck, P. Tsakalides Journal: arXiv Year: 2018…
Authors: F. Ngolè Mboula, J-L. Starck Journal: arXiv Year: 2017 Download: ADS | arXiv…
Authors: S. Farrens, J-L. Starck, F. Ngolè Mboula Journal: A&A Year: 2017 Download:…
Authors: F. Ngolè Mboula, J-L. Starck, K. Okumura, J. Amiaux, P. Hudelot Journal:…
Authors: F. Ngolè Mboula, J-L. Starck, S. Ronayette, K. Okumura, J. Amiaux Journal:…