Faster and better sparse blind source separation through mini-batch optimization
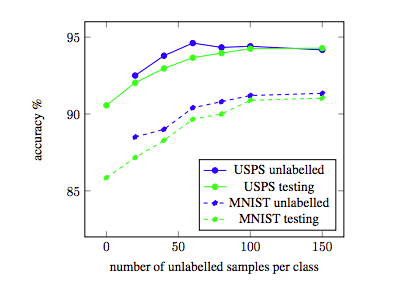
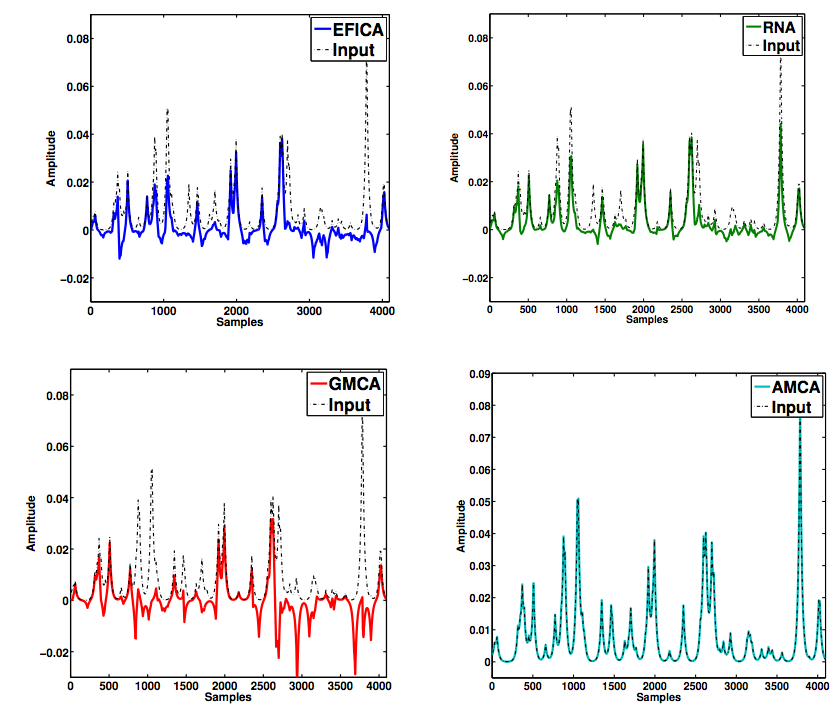
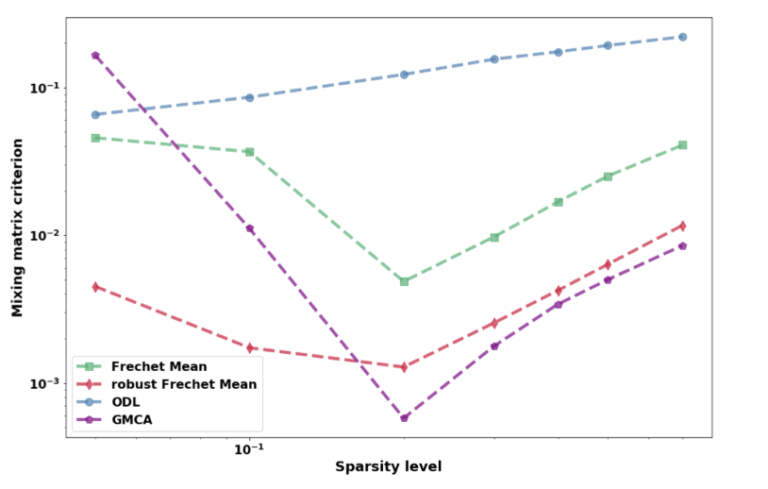
Sparse Blind Source Separation (sBSS) plays a key role in scientific domains as different…
Sparse Blind Source Separation (sBSS) plays a key role in scientific domains as different…
Authors: Khanh-Hung Tran, Fred-Maurice Ngole-Mboula, J-L. Starck Journal: SIAM Journal on Imaging Sciences…
The paper “Sparsity and adaptivity for the blind separation of partially correlated sources” has…
Title : Sparse decompositions for advanced data analysis of hyperspectral data in biological applications…