Rethinking data-driven point spread function modeling with a differentiable optical model
Authors: Tobias Liaudat, Jean-Luc Starck, Martin Kilbinger, Pierre-Antoine Frugier Journal: Inverse Problems Year:…
J.-L. Starck’s publications
Authors: Tobias Liaudat, Jean-Luc Starck, Martin Kilbinger, Pierre-Antoine Frugier Journal: Inverse Problems Year:…
Authors: Utsav Akhaury, Jean-Luc Starck, Pascale Jablonka, Frédéric Courbin, Kevin Michalewicz Journal: A&A Year: 2022 DOI: …
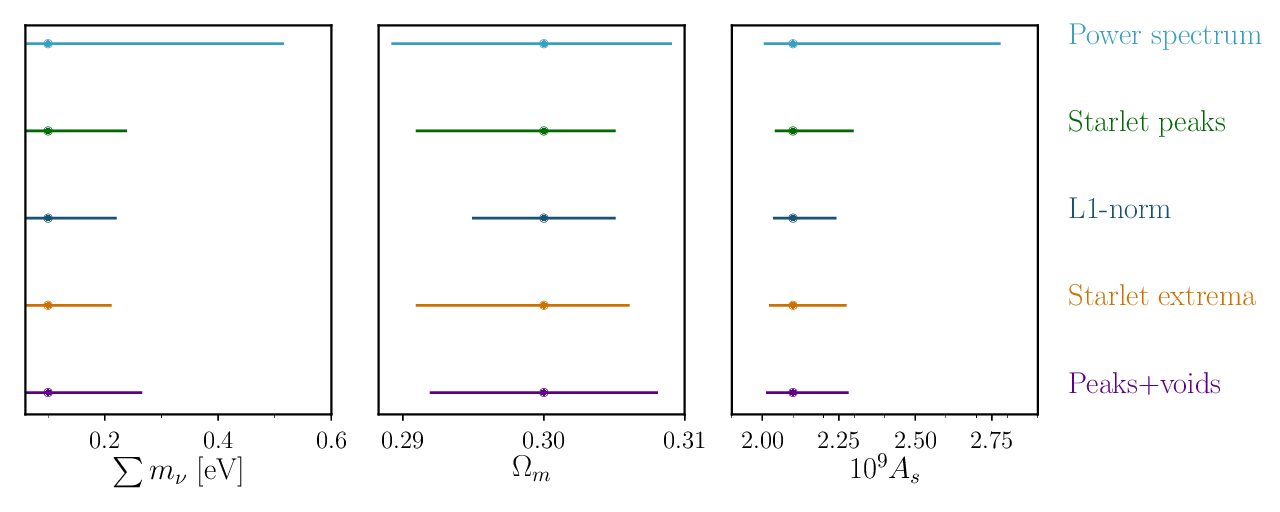
Authors: E. Ayçoberry, V. Ajani, A. Guinot, M. Kilbinger, V. Pettorino, S. Farrens,…
Authors: A. Guinot, M. Kilbinger, S. Farrens, A. Peel, A. Pujol, M. Schmitz,…
Authors: S. Farrens, A. Guinot, M. Kilbinger, T. Liaudat , L. Baumont, X.…
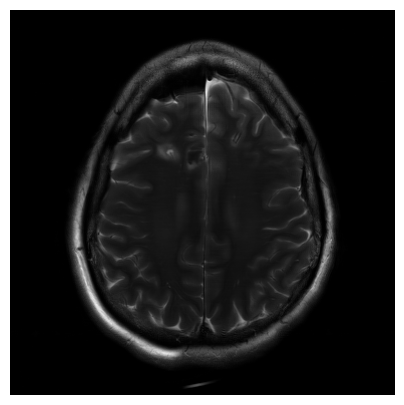
Deep Learning has become a very promising avenue for magnetic resonance image (MRI) reconstruction.…
Deep neural networks have recently been thoroughly investigated as a powerful tool for MRI…
Authors: Virginia Ajani, Jean-Luc Starck, Valeria Pettorino Journal: Astronomy & Astrophysics , Forthcoming…
Accelerating MRI scans is one of the principal outstanding problems in the MRI research…
Context. Galaxy imaging surveys observe a vast number of objects that are affected by…