La matière noire de la toile cosmique révélée par l’effet de lentille gravitationnelle
Une nouvelle étape a été franchie dans le domaine des lentilles gravitationnelles faibles (weak…
Une nouvelle étape a été franchie dans le domaine des lentilles gravitationnelles faibles (weak…
Au sein de la collaboration internationale UNIONS, des scientifiques de l’Institut de recherche sur…
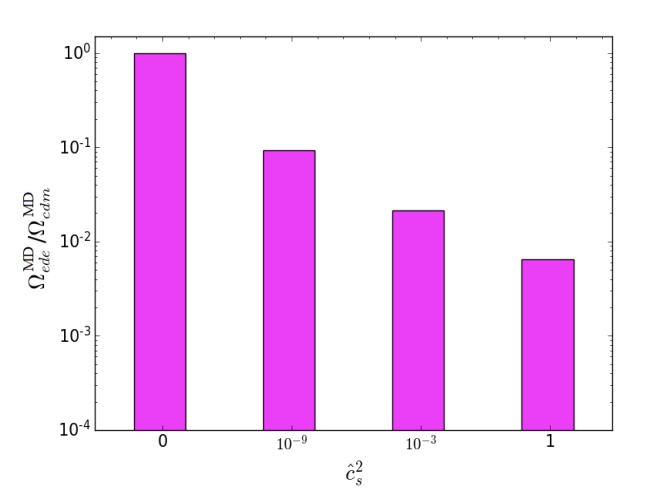
Authors: Adrià Gómez-Valent, Ziyang Zheng, Luca Amendola, Valeria Pettorino, Christof Wetterich Journal: PRD Year: 07/2021 Download:…
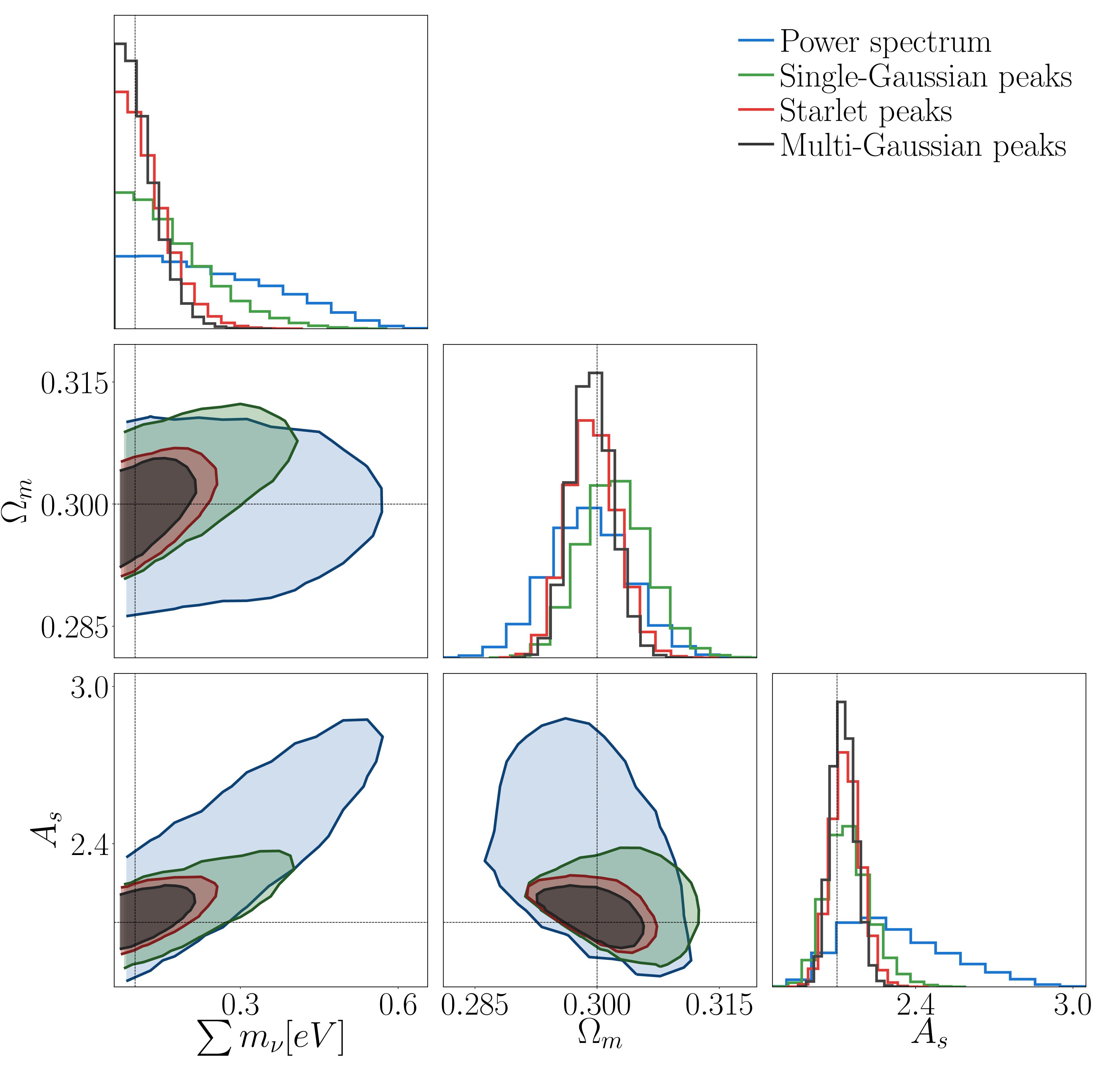
Authors: Virginia Ajani, Jean-Luc Starck, Valeria Pettorino Journal: Astronomy & Astrophysics , Forthcoming…
Authors: M. Kilbinger, A. Pujol Language: Python Download: GitHub Description: shear_bias is a…
Context. Galaxy imaging surveys observe a vast number of objects that are affected by…
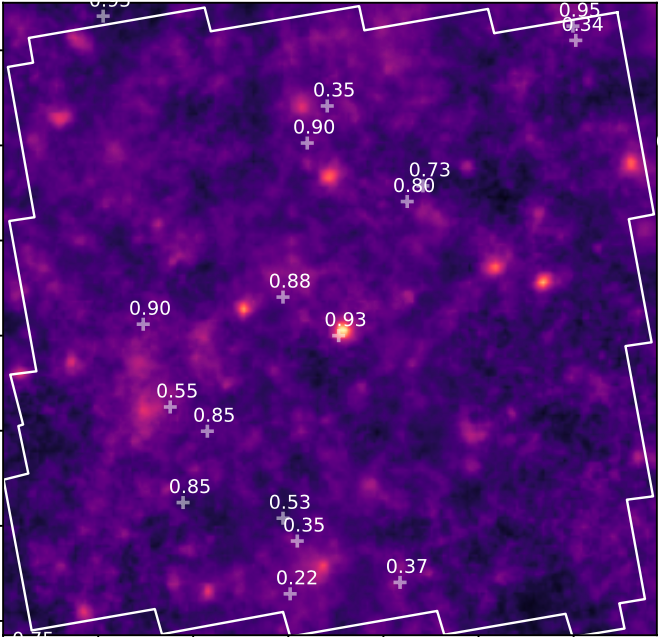
The Dark Matter present in the Large-Scale Structure of the Universe is invisible, but…
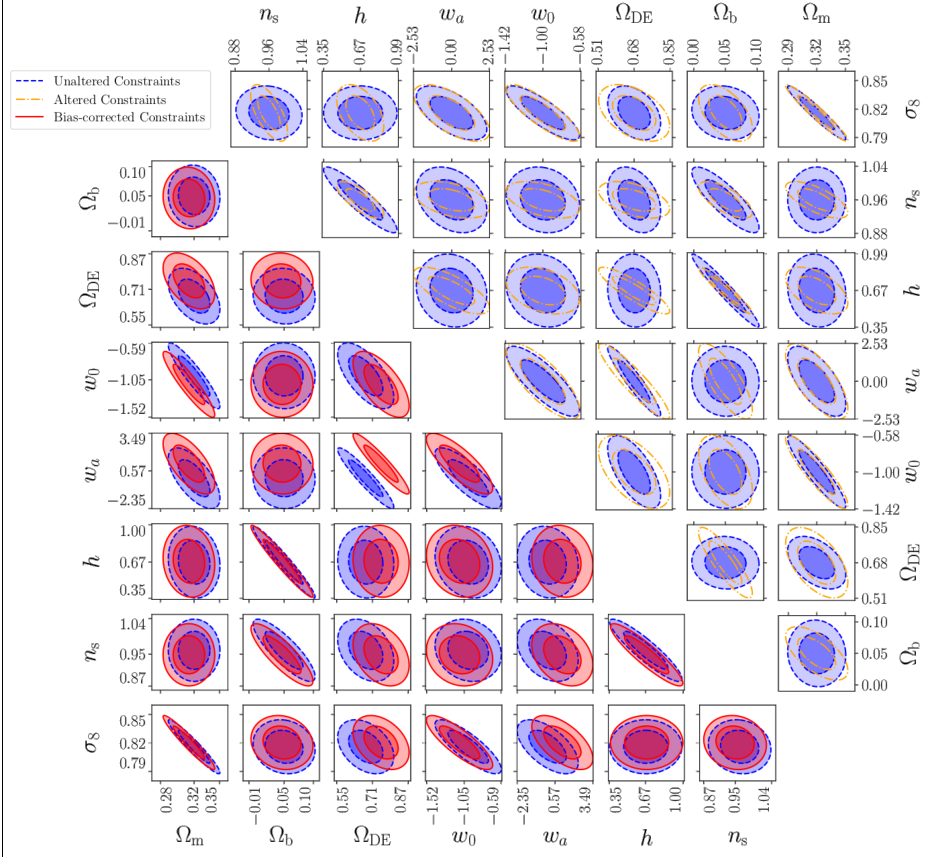
Authors: A.C. Deshpande, ..., S. Casas, M. Kilbinger, V. Pettorino, S. Pires, J.-L. Starck,…
Authors: Euclid Collaboration, P. Paykari, ..., S. Farrens, M. Kilbinger, V. Pettorino, S. Pires,…
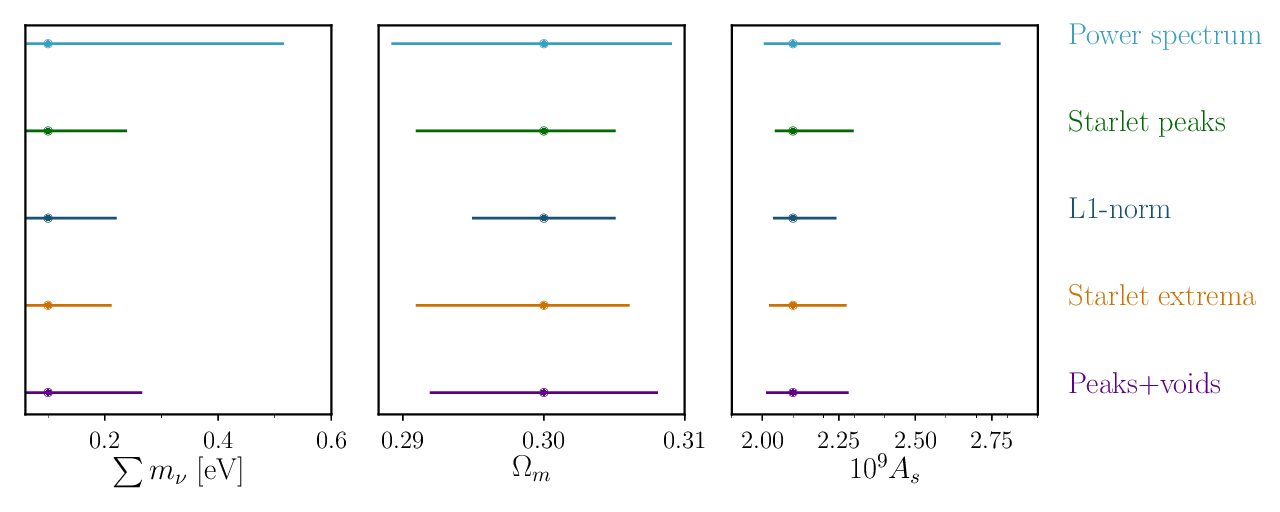
Massive neutrinos influence the background evolution of the Universe as well as the growth…