A Distributed Learning Architecture for Scientific Imaging Problems
Authors: A. Panousopoulou, S. Farrens, K. Fotiadou, A. Woiselle, G. Tsagkatakis, J-L. Starck, P. Tsakalides Journal: arXiv Year: 2018…
Publications related to the DEDALE project.
Authors: A. Panousopoulou, S. Farrens, K. Fotiadou, A. Woiselle, G. Tsagkatakis, J-L. Starck, P. Tsakalides Journal: arXiv Year: 2018…
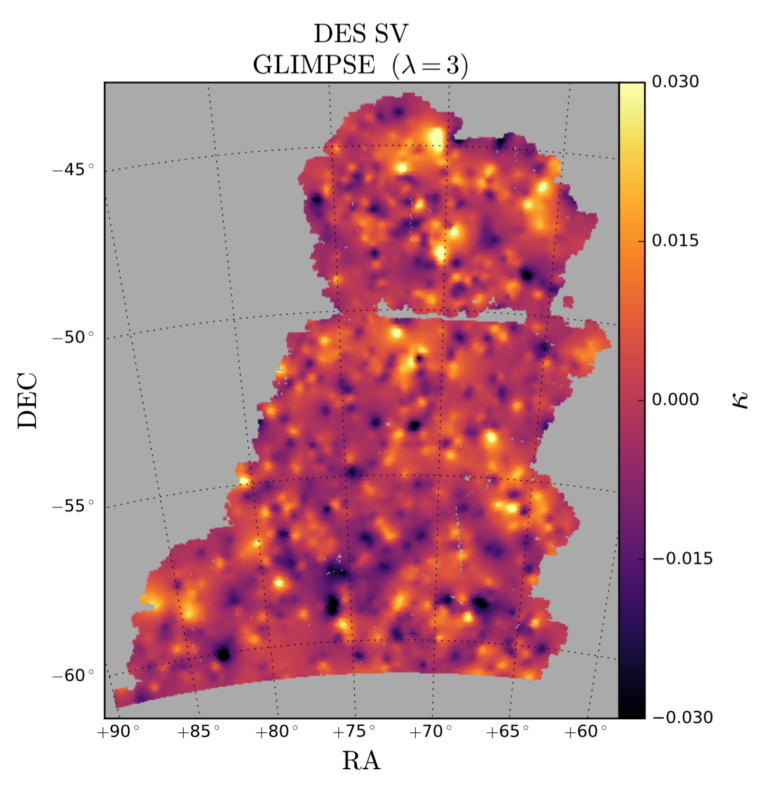
Authors: N. Jeffrey, F. B. Abdalla, O. Lahav, F. Lanusse, J.-L. Starck, et al Journal: Year:…
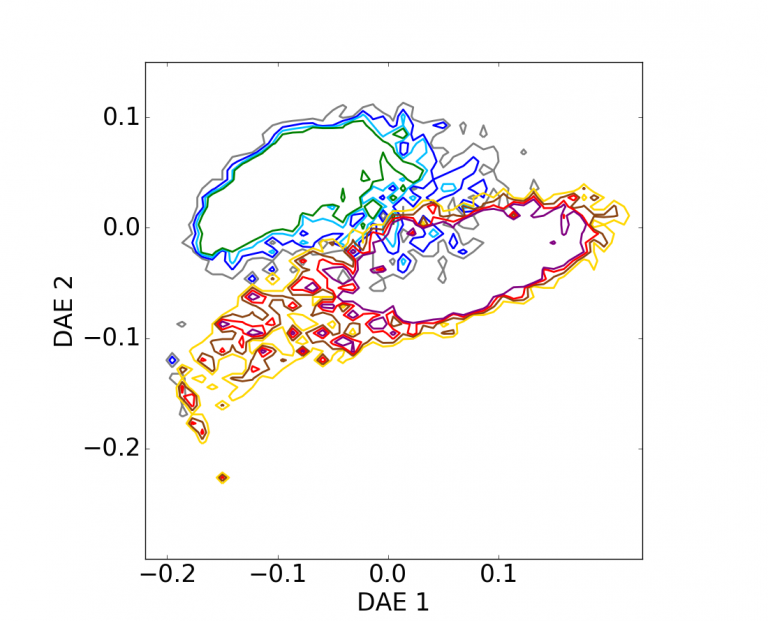
Authors: M.A. Schmitz, M. Heitz, N. Bonneel, F.-M. Ngolè, D. Coeurjolly, M. Cuturi,…
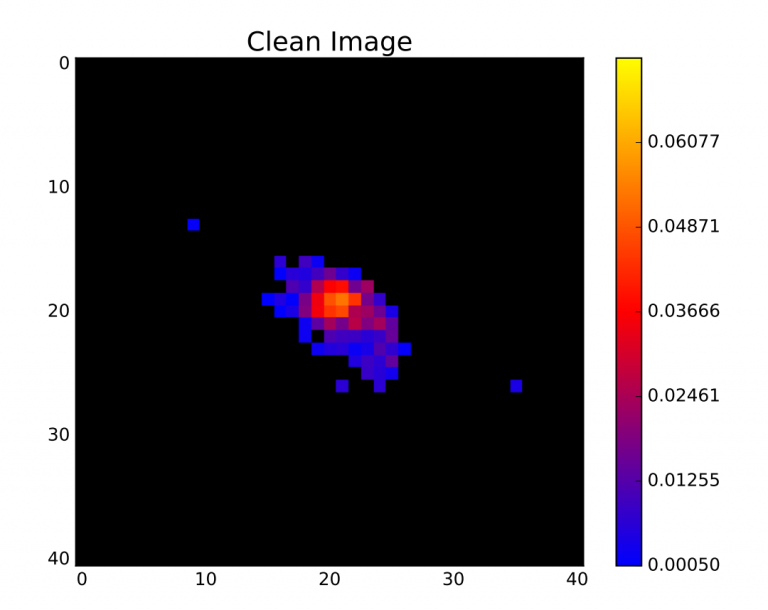
Authors: Frontera-Pons, J., Sureau, F., Bobin, J. and Le Floc'h E. Journal: Astronomy…
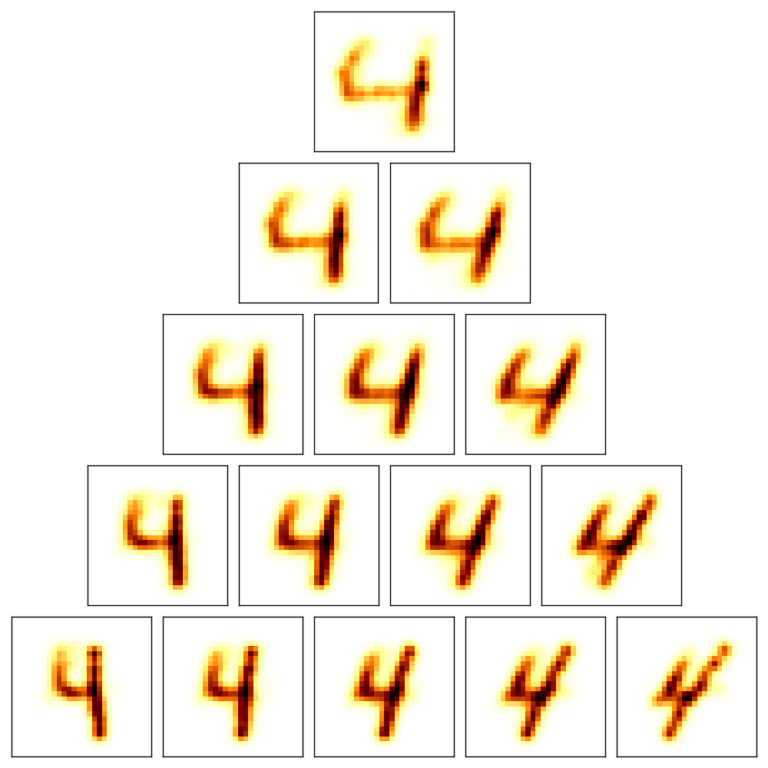
Authors: S. Farrens, J-L. Starck, F. Ngolè Mboula Journal: A&A Year: 2017 Download:…