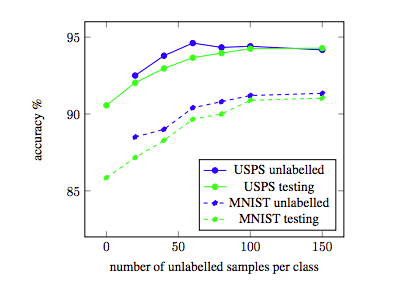
Semi-supervised dictionary learning with graph regularization and active points
Authors: Khanh-Hung Tran, Fred-Maurice Ngole-Mboula, J-L. Starck Journal: SIAM Journal on Imaging Sciences…
Publications related to machine learning
Authors: Khanh-Hung Tran, Fred-Maurice Ngole-Mboula, J-L. Starck Journal: SIAM Journal on Imaging Sciences…
Authors: Florent Sureau, Alexis Lechat, J-L. Starck Journal: Astronomy and Astrophysics Year: 2020…
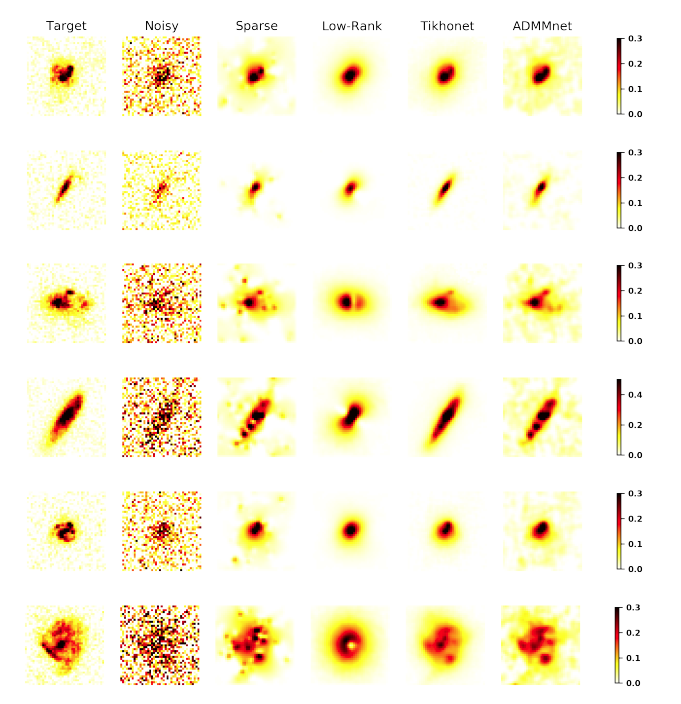
Deep learning is starting to offer promising results for reconstruction in Magnetic Resonance Imaging…
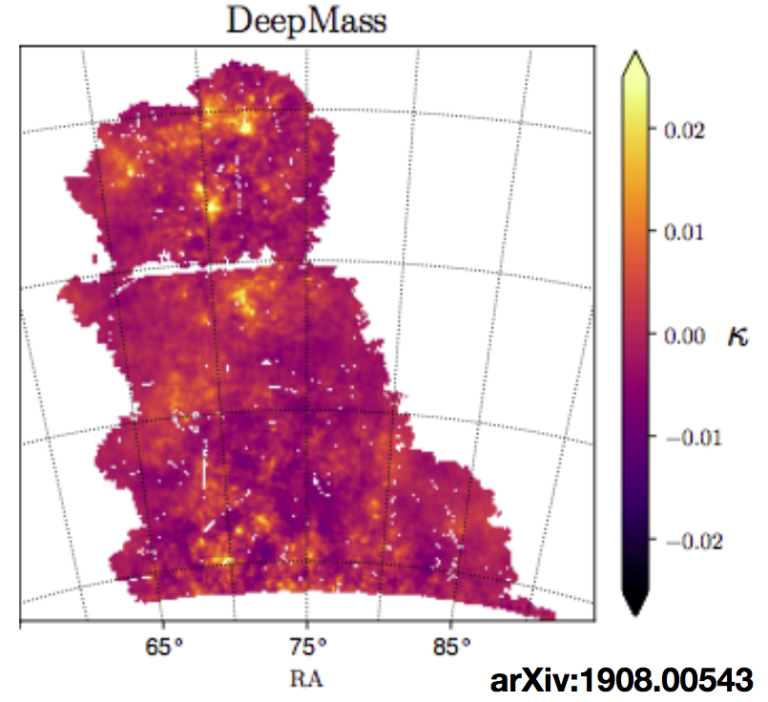
This is the first reconstruction of dark matter maps from weak lensing observational data…
Authors: A. Peel, F. Lalande, J.-L. Starck, V. Pettorino, J. Merten, C. Giocoli,…
Authors: J. Merten, C. Giocoli, M. Baldi, M. Meneghetti, A. Peel, F. Lalande,…
Authors: M.A. Schmitz, M. Heitz, N. Bonneel, F.-M. Ngolè, D. Coeurjolly, M. Cuturi,…
Authors: Frontera-Pons, J., Sureau, F., Bobin, J. and Le Floc'h E. Journal: Astronomy…