UNIONS: The impact of systematic errors on weak-lensing peak counts
Authors: E. Ayçoberry, V. Ajani, A. Guinot, M. Kilbinger, V. Pettorino, S. Farrens,…
Publications for S.Farrens
Authors: E. Ayçoberry, V. Ajani, A. Guinot, M. Kilbinger, V. Pettorino, S. Farrens,…
Authors: A. Guinot, M. Kilbinger, S. Farrens, A. Peel, A. Pujol, M. Schmitz,…
Authors: S. Farrens, A. Guinot, M. Kilbinger, T. Liaudat , L. Baumont, X.…
Authors: L. Ingoglia, G. Covone, M. Sereno, ..., S. Farrens, et al. Journal:…
Authors: S. Farrens, A. Lacan, A. Guinot, A. Z. Vitorelli Journal: A&A Year:…
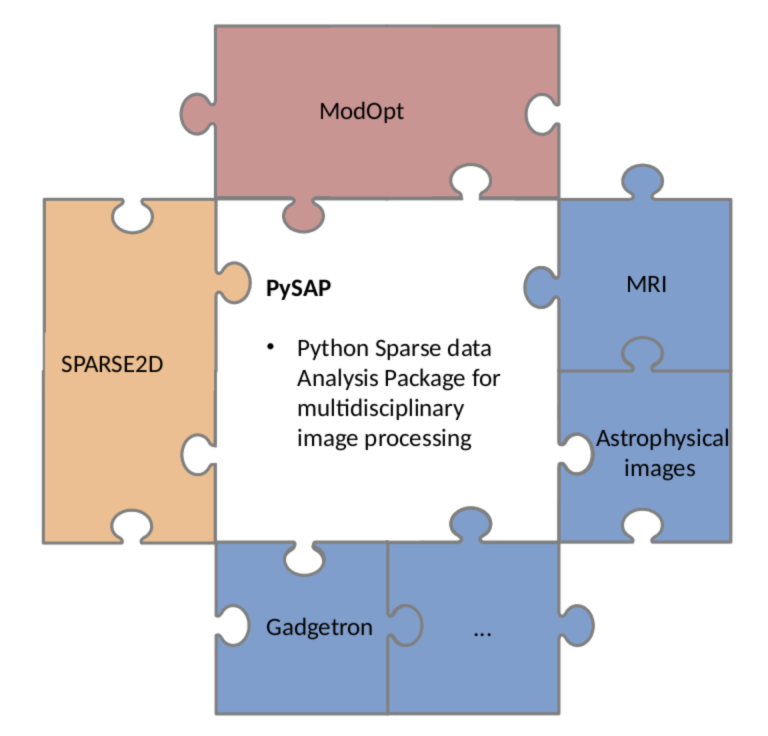
Authors: S. Farrens, A. Grigis, L. El Gueddari, Z. Ramzi, Chaithya G. R.,…
Authors: Euclid Collaboration, P. Paykari, ..., S. Farrens, M. Kilbinger, V. Pettorino, S. Pires,…
Authors: Euclid Collaboration, R. Barnett, ..., S. Farrens, M. Kilbinger, V. Pettorino, F. Sureau,…
Authors: Euclid Collaboration, R. Adam, ..., S. Farrens, et al. Journal: A&A Year: 2019…
Authors: A. Panousopoulou, S. Farrens, K. Fotiadou, A. Woiselle, G. Tsagkatakis, J-L. Starck, P. Tsakalides Journal: arXiv Year: 2018…