ShapePipe
Authors: S. Farrens, A. Guinot, M. Kilbinger, T. Liaudat Language: Python Download: GitHub…
All CosmoStat software
Authors: S. Farrens, A. Guinot, M. Kilbinger, T. Liaudat Language: Python Download: GitHub…
Deep Learning has become a very promising avenue for magnetic resonance image (MRI) reconstruction.…
Deep neural networks have recently been thoroughly investigated as a powerful tool for MRI…
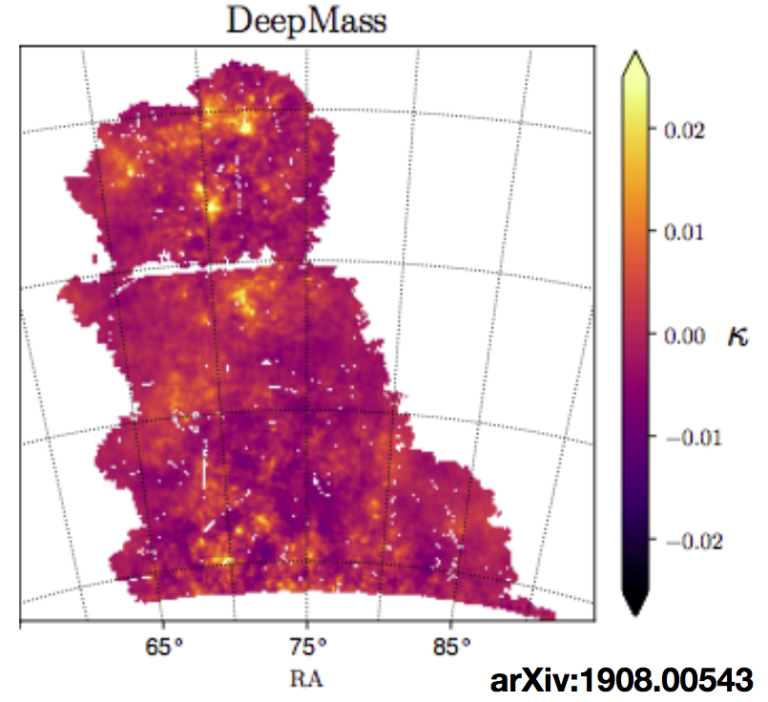
Authors: N. Jeffrey, F. Lanusse Language: Python Download: GitHub Description: Deep learning to…
Authors: M. Kilbinger, A. Pujol Language: Python Download: GitHub Description: shear_bias is a…
Authors: M. Jiang Language: Python Download: Python Description: A toolbox for solving joint…
Authors: A. Peel Language: Python Download: GitHub Description: A collection of python codes…
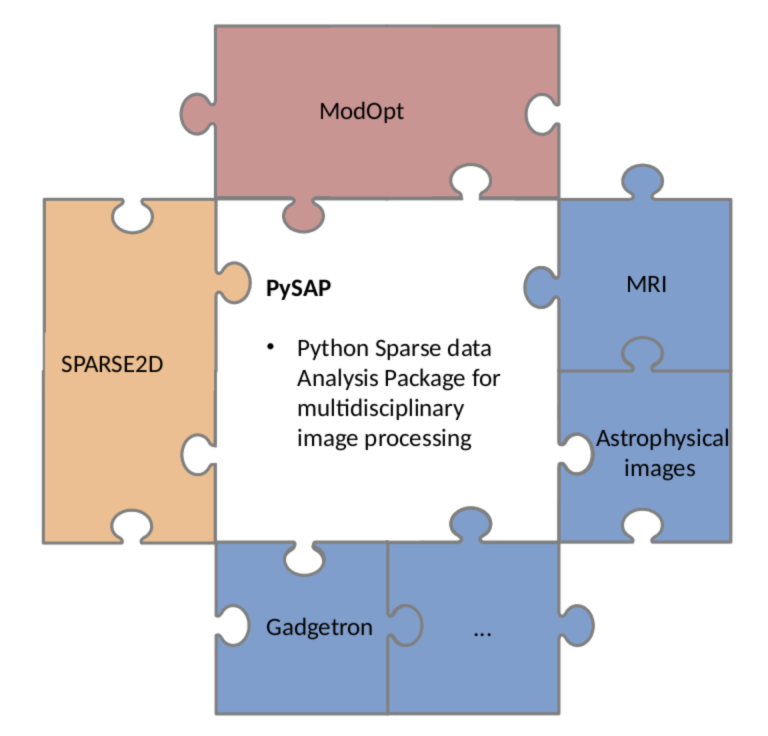
Authors: S. Farrens, Z. Ramzi, Contributors Language: Python Download: GitHub Description: ModOpt is…
Authors: S. Farrens, A. Grigis, L. El Gueddari, Z. Ramzi, Chaithya G. R.,…
Authors: P. Touboul, G. Metris, M. Rodrigues, Y. André, Q. Baghi, J. Bergé, D.…