Title : Sparse decompositions for advanced data analysis of hyperspectral data in biological applications
Abstract : Blind source separation aims at extracting unknown source signals from observations where these sources are mixed together by an unknown process. However, this very generic and non-supervised approach does not always provide exploitable results. Therefore, it is often necessary to add more constraints, generally arising from physical considerations, in order to favor the recovery of sources with a particular sought-after structure. Non-negative matrix factorization (NMF), which is the main focus of this thesis, aims at searching for non-negative sources which are observed through non-negative linear mixtures.
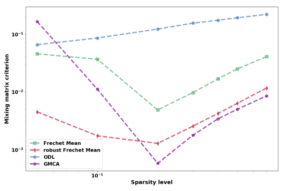
In some cases, further information still remains necessary in order to correctly separate the sources. Here, we focus on the sparsity concept, which helps improving the contrast between the sources, while providing very robust approaches, even when the data are contaminated by noise. We show that in order to obtain stable solutions, the non-negativity and sparse constraints must be applied adequately. In addition, using sparsity in a potentially redundant transformed domain could allow to capture the structure of most of natural image, but this kind of regularization proves difficult to apply together with the non-negativity constraint in the direct domain. We therefore propose a sparse NMF algorithm, named nGMCA (non-negative Generalized Morphological Component Analysis), which overcomes these difficulties by making use of proximal calculus techniques. Experiments on simulated data show that this algorithm is robust to additive Gaussian noise contamination, with an automatic control of the sparsity parameter. This novel algorithm also proves to be more efficient and robust than other state-of-the-art NMF algorithms on realistic data.
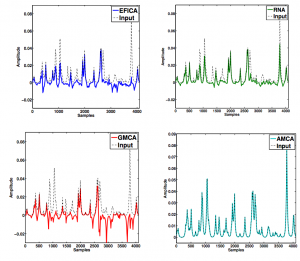
Finally, we apply nGMCA on liquid chromatography – mass spectrometry data. Observation of these data show that they are contaminated by multiplicative noise, which greatly deteriorates the results of the NMF algorithms. An extension of nGMCA was designed to take into account this type of noise, thanks to the use of a non-stationary prior. This extension is then able to obtain excellent results on annotated real data.